



Introduction
Within its paper on ‚Refining the Design principles of Identity Relationship Management‘ [1], the Kantara Workgroup for Identity Relationship Management (IRM) defined the criteria a system should follow to enable representation and management of identity relationships.
In the course of its exploration, two things have become apparent: The need for a type of ‚Relationship Manager‘ and a Relationship ‚Notation‘ Language.
The document you are reading right now gives a first introduction and view on the topic of a ‚notation‘ language, and is one of the contributions from WedaCon to the mentioned workgroup. While concentrating on this, we will also see a few links and mentions of the functionality of a ‚relationship manager‘.
Notation ‚language‘
Wikipedia explains ,Notations' as ,a system of graphics or symbols, characters and abbreviated expressions, used inter alias in artistic and scientific disciplines to represent technical facts and quantities by convention. Therefore, a notation is a collection of related symbols that are each given an arbitrary meaning, created to facilitate structured communication within a domain knowledge or field of study.' [2]
The Merriam Webster Dictionary declares it as ,a system of characters, symbols, or abbreviated expressions used in an art or science or in mathematics or logic to express technical facts or quantities'.
[3]With these two explanations, it becomes apparent that ‚notation language‘ is a tautology, as the term ‚notation‘ is just another word for ‚language‘: to describe facts using a convention (not necessarily using ‚words‘). The notation used for this document is known as ‚english‘.
Some relations
As already stated in the report, relationships are not new. Relational databases are the number one type of relational systems a reader might be familiar with. Architects and engineers in the profession of database design and implementation produce Entity Relation (ER) [4] models on a regular basis; so the question arise : Why do we need something special for IRM?
One of the reasons for this: while databases usually manage ‚local‘ data (within their tables and rows) only, IRM needs to be able to manage ‚disconnected‘ and remote data as well: To prove the relationship between Entity A (say: Alice) and Entity B (say: Dr. Bob), it might be necessary to link two different datasets (e.g. the patient database of Hospital C and the doctors‘ database of hospital D (as Dr. Bob is working there).
But that does not mean we need to re-invent the wheel: By investigating ER-Modells we can learn a lot about the requirements and principles of notation.
Notations and models
As mentioned, notations can consist of graphics, symbols or characters. Especially in technical topics, symbols are used to describe and visualize.
We already talked about ER-Models, which describe relationships between instances of entities in a given knowledge domain. Modeling facts using an abstract data model is done using symbols to form a graphical notation. This notation is perfect to visualize relations between entities , helping humans to understand and use this information to design (relational) systems. It makes a given fact human-understandable, but usually lacks the ability for machine interpretation.
What we are looking for is something that can help/ support a ‚relationship manager‘ doing its job. And this notation needs to be machine-interpretable. However: it would be nice if it is also human-understandable.
Its time to define the requirements for such a notation in more detail.
Requirements for Relationship Notations
A notation for identity relations needs to be able to describe facts (relations) between disconnected and remote domains and/or entities (Hospital C and Hospital D), and it needs to be able to either share concepts (‚what is a patient‘?) or understand the concepts used within a relation.
As it is per definition used for inter-connectivity, using standards (if available) is a must.
So far, as a result we have collected the following four basic requirements a relationship notation should provide:
- Support the six design principles Provable, Constrainable, Mutable, Revocable, Delegable and Scalable from the IRM Design Principles Document.
- Machine-interpretable and human-understandable.
- Support disconnected and remote entities, concepts and domains.
- Standards-oriented.
Symbols, objects and concepts
Any sign (symbol, word, sound) in itself has no meaning if not explained somewhere. We do use signs all the time without caring about this simple fact. The reason: we have a common understanding and expectation of the signs. If, during communication, the ‚sender‘ and the ‚receiver‘ have different expectations (understandings) of the signs, communication fails.
As a result, a notation for relations needs to provide a way to enable the sender and receiver to understand the claim made on a relation. Lets have a view on a simple statement about a relation:
This lightbulb is made by ACME Corporation
I think we can agree, one of the requirements for relationship notation is already met: this sentence is human-understandable. Apart from the fact that we are able to read and understand english, and know concepts / entities like ‚lightbulb‘ or ‚is made by‘, there is more in this statement to explore: it uses a common form we have learned in school:

In its simplest form, any relation can be described using this ‚subject-predicate-object‘ pattern. Lets use a more ‚techie‘ oriented variant of the above to further investigate its potential:
lightbulb:A is_made_by Corporation:ACME
Still, this statement consist of a subject (‚lightbulb:A‘), a predicate (‚is_made_by‘) and an object (‚Corporation:ACME‘). And it can still be understood by humans, but is this machine-interpretable? If you are familiar in IT (I am guessing you are), you might come to the conclusion that this variant is at least easier to ‚read‘ by machines. But being able to read (store into a variable) does not help at all: You (more precise: a relationship manager) needs to know how to interpret those strings.
What is required here is a way to understand the concepts represented by these strings: we need to convert the strings into ‚things‘. And while talking about things: it would also be beneficial to be able to uniquely identify the given thing as an instance of the concept we are describing.
Graphs
In mathematics, and more specifically in graph theory, a graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense "related".‘ [5], states Wikipedia in its articles about graphs.
Graphs consist of nodes (also known as vertices or points) and edges (arcs, lines). The simplest form can be thought of two nodes, connected by lines (on its edges). Sounds familiar?
Correct: A graph describes a relationship between two nodes: one node is the subject, the other one the object, and the relationship between them is the predicate.
Back to our lightbulb example, lets assume we have three lightbulbs from two different vendors
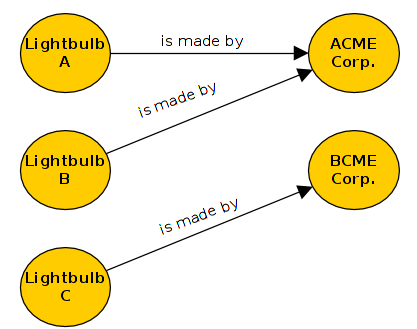
This picture can also be described using a notation:
-
@prefix lb: http://notationexamples.irm/lightbulb# .
@prefix lb: http://notationexamples.irm/company# .
@prefix lb: http://notationexamples.irm/relations# .
# three lightbulbs made by two different companies
lb:A pre:is_made_by co:ACME .
lb:B pre:is_made_by co:ACME .
lb:C pre:is_made_by co:BCME .
Note the ‚prefix‘ declaration: it defines a namespace for the type of entities and their properties, which is an arbitrary URI and identifier offering uniqueness for concepts and instances within its namespace.
The notation we have used here is based on the Resource Description Framework (RDF).
Its time to cover another one of our requirements: Standard orientation.
Resource Description Framework (RDF)
RDF is a specification by the World Wide Web Consortium (W3C) and was adopted as a recommendation in 1999. The RDF model is based on the ideas of making statements about uniquely identifiable resources in the already mentioned form of ‚subject-predicate-object‘, also known as ‚triple‘. The subject denotes the resource, and the predicate denotes traits or aspects of the resource, expressing a relation between the subject and the object. [6]
While the object can be a literal (string, numbers) as well, the possibility to use a unique (uniform) identifier (URI) provides interconnectivity in much the same way as what URLs (uniform resource locator) gave us for the World Wide Web.
The URI defines namespaces for the subject and object, and the same is true for the predicate: The type of relation is usually bound to one as well. This namespace might be available and known locally only, but with the extension of a URI and RDF specifications we are able to describe the type of relation (e.g. the concept of ‚is_made_by‘) in a way which enables remote systems to ‚understand‘ this claim and act accordingly.
Simplified, this definition can be seen as a vocabulary describing the specific notation used within the given concept, bound to a namespace.
Vocabularies and Ontologies
Vocabularies for the given use cases are also known as ‚ontologies‘, and we have a standard from W3C for this as well: the ‚Web Ontology Language‘, short ‚OWL‘ (yes, not WOL, as OWL is easier to pronounce. Not kidding here). Describing OWL and all its features would make this doc exploding, so lets simplify this: it is built on top of RDF, and uses triples as well.
The nice thing with OWL: it allows you to describe concepts using triples in much the same way as you can describe your data in triples. This includes boundaries and rules a given graph (statement, triple) can provide, allowing much more granulated rule sets than traditional rule sets and schemata can provide.
With our RDF example about lightbulbs, we already have defined a namespace for our claims. By adding metadata to those definitions, we can further enhance the meaning of the statements. Because of the usage of URI‘s instead of literals, we can include definitions from other vocabularies as well.
|
01 @prefix lb: http://notationexamples.irm/lightbulb# . 02 @prefix co: http://notationexamples.irm/company# . 03 @prefix pre: http://notationexamples.irm/relations# . 04 @prefix rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns# . 05 @prefix rdfs: http://www.w3.org/2000/01/rdf-schema# . 06 @prefix owl: http://www.w3.org/2002/07/owl# 07 08 # three lightbulbs made by two different companies 09 10 lb:A pre:is_made_by co:ACME . 11 lb:B pre:is_made_by co:ACME . 12 lb:C pre:is_made_by co:BCME . 13 14 #describing the predicate ‚is_made_by‘ 15 pre:is_made_by rdf:type rdf:Property . 16 pre:is_made_by rdf:comment „the relation between a product and its producer“ . 17 pre:is_made_by rdf:type owl:SymetricProperty . 18 pre:has_produced owl:inverseOf pre:is_made_by . |
A quick walk through on our additions (which are shown in bold):
In line 04-06 we have defined namespaces for three new prefixes rdf, rdfs and owl. Those provide a URI for the vocabularies that will provide further details and meaning to our information.
Line 15 and 16 are statements about the nature of ‚pre:is_made_of‘ as a property which is used to describe the relation between something that is produced and something that does produce.
Line 17 and 18 go even further by describing a new relation (and allows for implicit knowledge) about the inverse relation between a producer and a product.
As all those statements use a W3C-Standard, they can easily be used for interoperability. OWL provides the necessary functionality to deal with information, and not only plain data. It is, as RDF in general, a key technology for the semantic web and linked data. [7]
Implicit and explicit relations
In our example, we now have explicit relations (A is produced by B) and implicit relations (B has produced A). Although we have not explicitly declared a given company that has produced a given product (or an instance of it), the notation used for our statements allows for this ‚new‘ knowledge. This type of ‚intelligence‘ is easy for humans, but hard for machines.
As in any profession, despite the importance to know the details, we need to be able to ask the right questions. And to be able to do that, we need to know how to ask. For (relational) databases, we have SQL, directories are queried using LDAP-Queries, and triplestore databases, sometimes referenced as ‚Graph-Databases‘ have their own query language as well: SPARQL, which is, again, a W3C standard. [8]
Here is an example of a SPARQL query (and its results) on our lightbulb example. The data read is exactly what we have defined in the section about vocabularies and ontologies. A SPARQL client would be able to query the endpoint to get the required information on what to expect and the meaning of the statements.

Query Language vs Notation requirements
If our SPARQL Client is OWL aware, it would be automatically able to use the implicitly available information. To keep things simple here, we will do the explicit query here, to show us all lightbulbs produced by ACME Corporation:
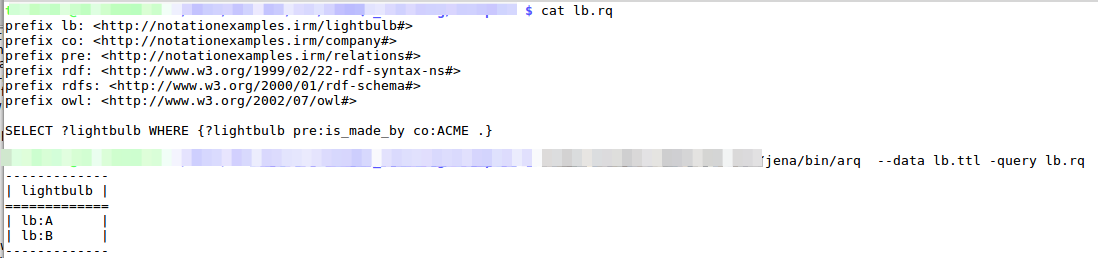
The example above does only return the subject (as we have asked). However, the result could be a real graph again, allowing for further work on the relations that are available.
SPARQL is able to manipulate information stored in RDF (subject predicate object) format. Its flexibility also allows to retrieve unstructured data and generate new triples from that data, using externally defined ontologies and additional data sources.
The system used for storing the data does not need to be a graph-database or a ‚triplestore‘. What is required is an interface which understands this query language: a SPARQL-Endpoint.
While SPARQL is the query language, RDF and OWL are the notations used to describe relations.
Together they provide the ability to generate new triples (and knowledge) which makes them a perfect set of candidates for Identity Relationship Management:
- standardized
- machine interpretable (and still human readable with the help of ontologies)
- supports disconnection (by caching the remote ontological definitions)
- with the use of ontologies, it can provide any of the identified principles for IRM
Linked Data and Linked Entities
When talking about ontologies and semantics, the term ‚linked data‘ is something you inadvertently stumble across. With our links into wikipedia, we even use this technology actively: Wikipedia makes extensive usage of it to show facts related to a given subject.
In much the same way as linked data provides a way to interconnect several data sources and make combined use of it, ‚linked entities‘ would allow for much the same beneficial usage.
Relational Identity Management will most likely use very similar concepts, but this is something we need to investigate when talking about a ‚relationship manager‘.
Some Links for further reading
1 Kantara Initiative: Refining the Design Principles of Identity Relationship Management
2 Wikipedia: Notation
3 Merriam-Webster: Notation
4 Wikipedia: Entity-relationship model
5 Wikipedia: Graph theory
6 Wikipedia: Resource Description Framework
7 Wikipedia: Semantic Web Stack
8 Wikipedia: SPARQL
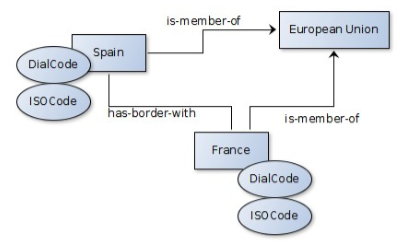 When speaking of Ontology we speak of classes of
entities and instances of these classes: individual entities.
They are related to each other through inheritance and relations
defined by properties. Additional 'knowledge' can be added using
axioms.
When speaking of Ontology we speak of classes of
entities and instances of these classes: individual entities.
They are related to each other through inheritance and relations
defined by properties. Additional 'knowledge' can be added using
axioms.
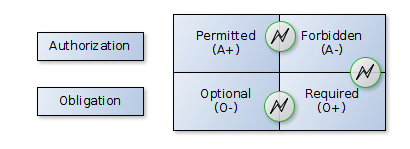 Based
on concepts of positive and negative evaluation of authorization
(granted / denied) and obligation (required / waived) our system
allows to create the relevant policies in constrained natural
language. In a case of policy conflict (e.g. required but
forbidden; Figure 2), the system automatically tries to resolve
the conflict based on predefined algorithms.
Based
on concepts of positive and negative evaluation of authorization
(granted / denied) and obligation (required / waived) our system
allows to create the relevant policies in constrained natural
language. In a case of policy conflict (e.g. required but
forbidden; Figure 2), the system automatically tries to resolve
the conflict based on predefined algorithms.
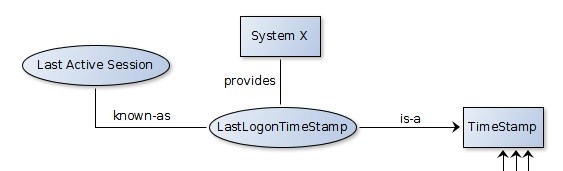
 timestamp representations
timestamp representations
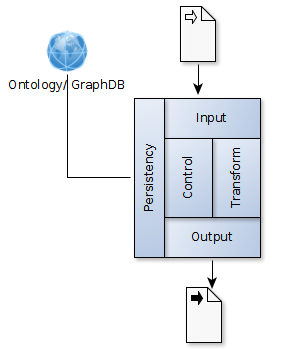 The Micro Services architecture consists of few
layers which have well defined input and output functions to the
respective layers.
The Micro Services architecture consists of few
layers which have well defined input and output functions to the
respective layers.





